Prototype Java in a Browser
→ See results as you type
→ Run it anywhere
Titanoboa lets you prototype your Java code in the browser
Titanoboa is an OSS workflow platform that puts strong emphasis on extensibility: it is crucial that you can easily create new integrations and new custom workflows in an agile fashion.
Many existing workflow solutions (like Mule or WSO2) are extensible, but usually it means you have to shut down your application server, fire off your IDE to do coding there, then once you think you are done you have to deploy, restart the server and pray that thinks are going to be working.
Others, like Zapier, offer just custom steps for JavaScript or Python, but not for Java.
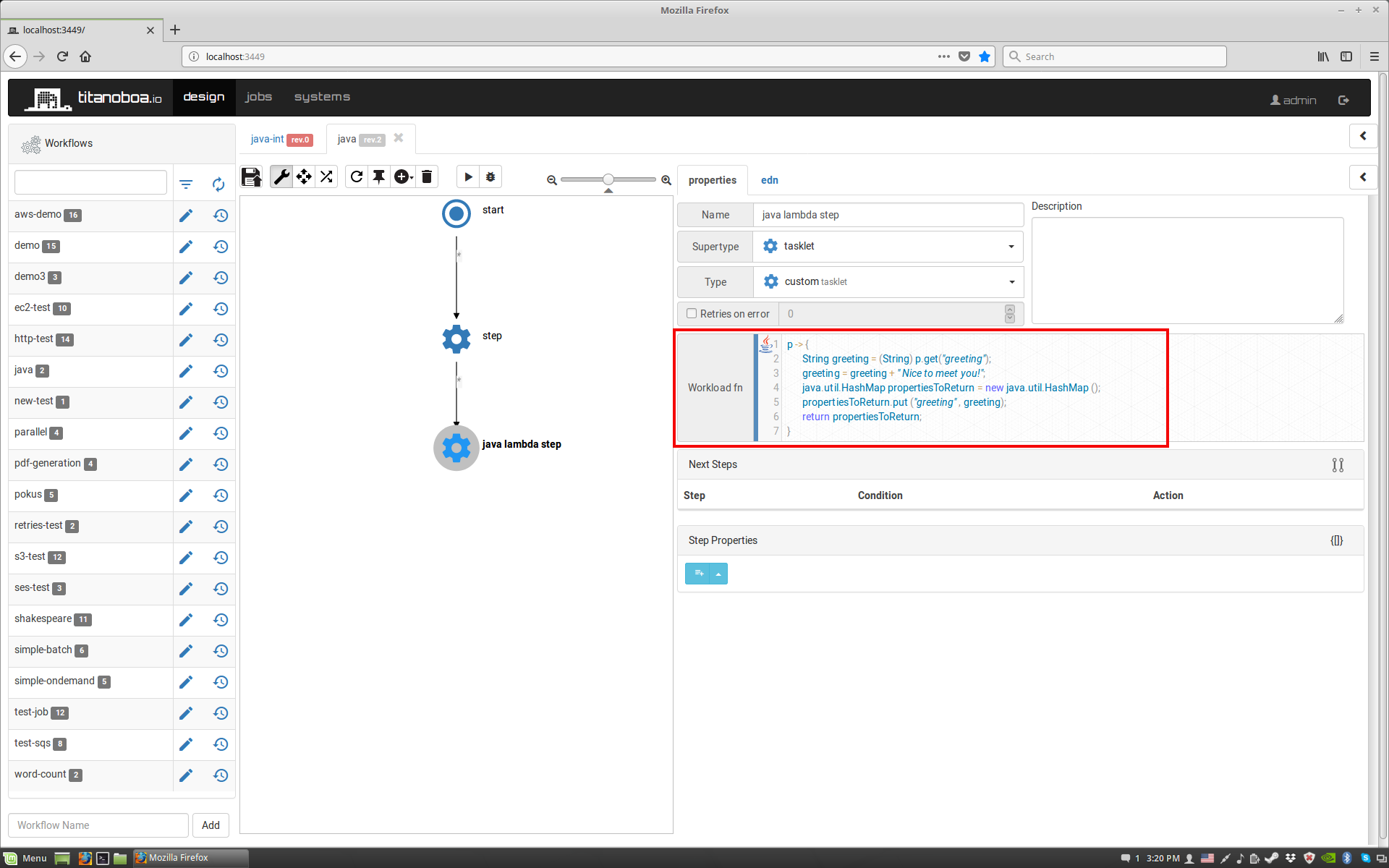
When creating Titanoboa I wanted to have all the flexibility to create custom workflow steps: you still can code in your IDE and then just deploy your code into Titanoboa via maven repository (instructions how to do it are here) – but you as well can rapidly prototype and test some ideas directly in Titanoboa’s GUI:
So the closest this comes to is Serverless and solution like AWS Step Functions, Azure Logic Apps or Google: with the difference that Titanoboa is an OSS and that you can run it in the cloud or on-premises.
I even added java REPL into browser, yay!
Example: Generate a bank statement and deliver it
To demonstrate what all you can do from a browser, I am going to create a sample workflow with a custom java code that will:- generate a PDF bank statement (using an OpenPDF library)
- upload it to an S3 bucket
- send it as an attachment via email
If you have not already, feel free to head to Titnoaboa's github page and follow the installation instructions.
Add Maven dependencies during runtime (to all your servers)
What would Java be without its ecosystem? We all use and love Java exactly because there are zillions of libraries out there we can easily use.
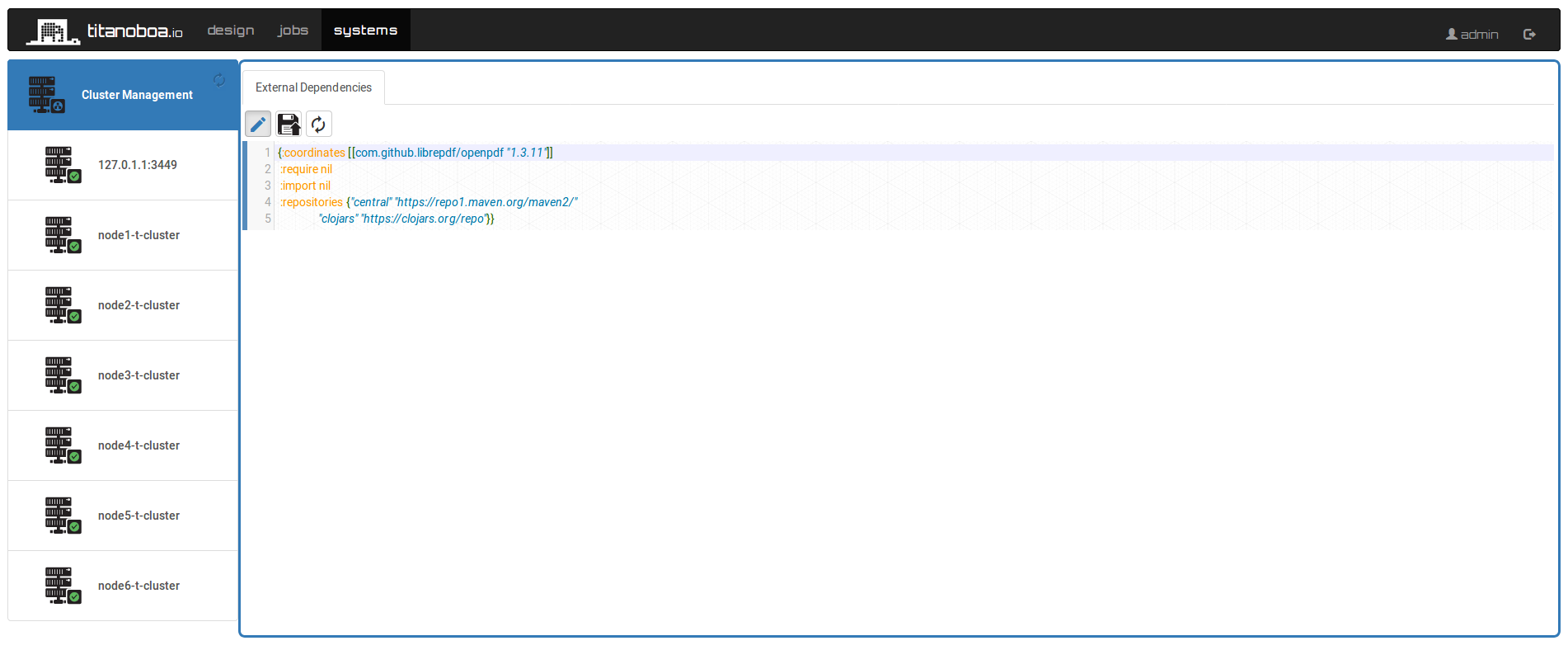
In Titanoboas’ GUI you can update the ext-dependencies.clj file (under Systems → Cluster Management → External Dependencies), where you can add any maven dependencies (for java or clojure).
In our example, if I want to use OpenPDF to generate a new pdf document I can just add following maven artefact (just need to click “edit” button first and “save” afterwards):
[[com.github.librepdf/openpdf “1.3.11”]]
Now the maven artifact is automatically loaded to all nodes in your Titanoboa cluster. No server or JVM restart is required.
Prototype Java code in browser
Just to showcase what can be done, I am going to create a new workflow and will create a new workflow step to generate a sample PDF bank statement using the OpenPDF library we just loaded via Maven.
Open Titanoboa GUI and in the Design tab create a new workflow. A new workflow with one step will open. In the Workflow-fn code editor, replace the default clojure code stub with java lambda
p → {}
.
Titanoboa will automatically recognize java code and will switch code highlighting to java mode.
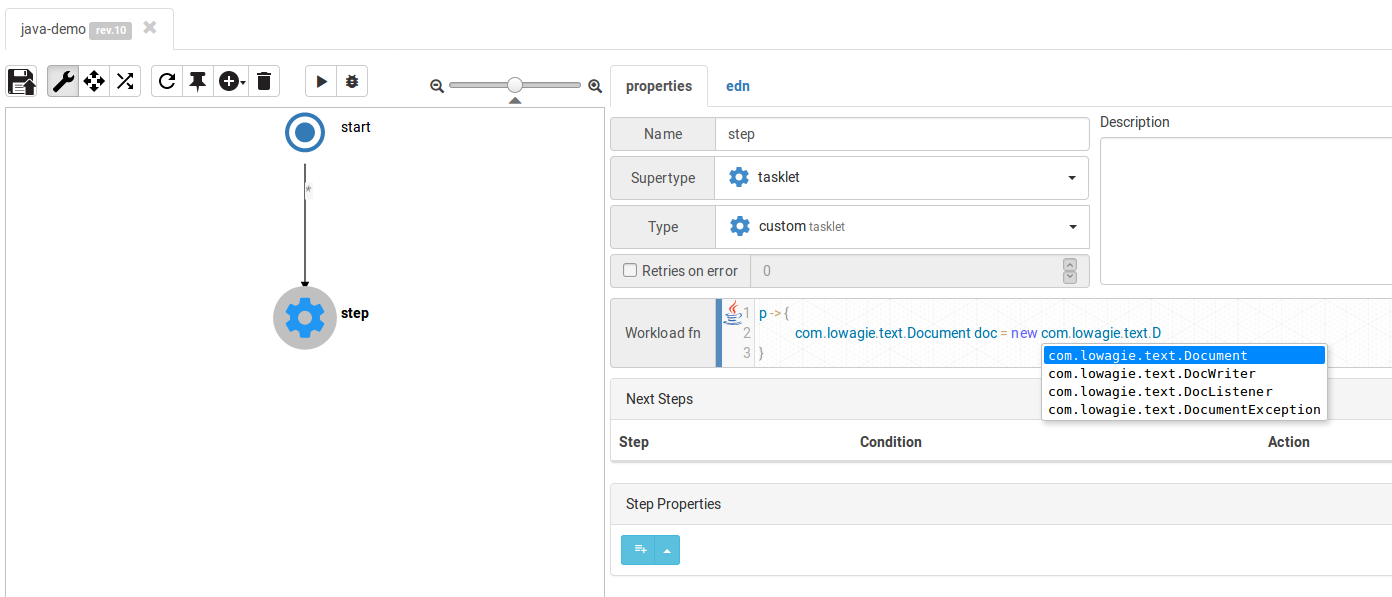
To see that the OpenPDF library is indeed on the classpath, you can use auto-comple: just type com.lowagie and hit Ctrl-Space – you should see a list of available packages and classes.
For our task will need to instantiate com.lowagie.text.Document:
In our demo step we may want to create a very simple PDF bank statement, that will contain a salutation and a table with transactions:

Use REPL to run and validate your java code as you type
Yes, you heard correctly! You can now use REPL for java as well! No need for a debugger if you just can run the code any time you want - just highlight all your java lambda code and pres Ctrl-Enter. This will run your lambda and pass onto it any properties you may have configured in your workflow. Result will be immediately shown:
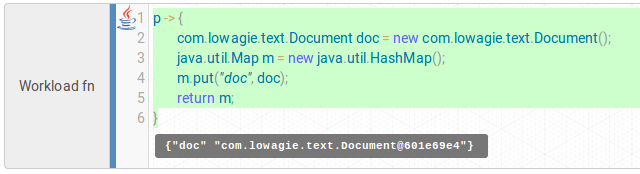
Here we can see that our lambda returned a map with a key “doc” and an instance of com.lowagie.text.Document as a value (GUI just converted it to text for us).
Create complex input properties and data structures in GUI
In titanoboa, you can define custom properties for your workflow on both job’s and individual step’s level. These dont have to be just some java (or clojure) literals – they can be also data structures (maps or vectors) or clojure expressions or any of their combinations. So it’s perfectly fine to have nested data structures etc.
For sake of our example, we will need a first name to print on our statement and also an array (aka vector) of transactions we will put on the statement. We can add them as job’s properties. They can be easily overriden or extended when starting a workflow job either via GUI or via API:
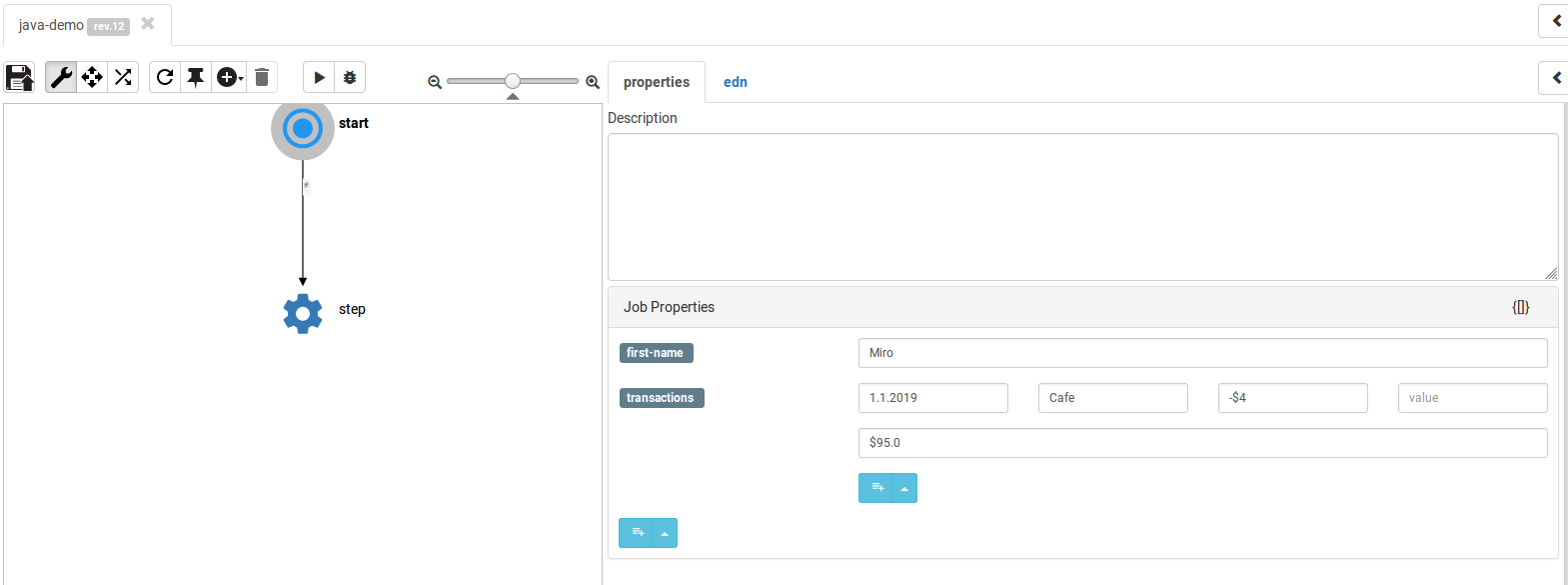
Finally, we can do a bit of coding to create a lambda that will get the properties from the input map and will generate a pdf into the workflow job’s working folder. We can also rename the step to something more sensible (e.g. “generate statement”):
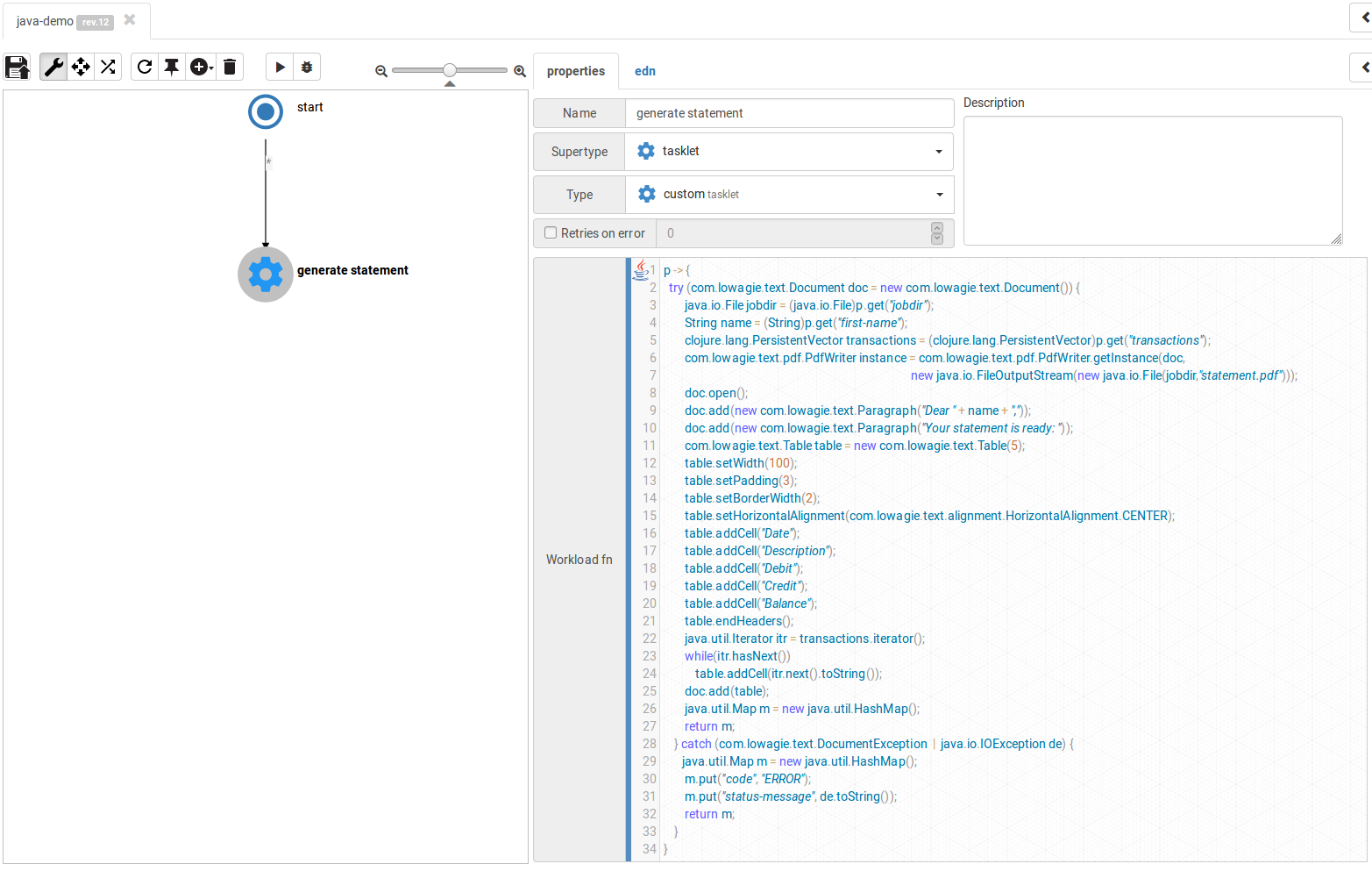
These three lines extract the input properties we need:
java.io.File jobdir = (java.io.File)p.get("jobdir");
String name = (String)p.get("first-name");
clojure.lang.PersistentVector transactions = (clojure.lang.PersistentVector)p.get("transactions");
The jobdir property is added to the workflow job automatically when the workflow is triggered. It refers to a unique working directory. (Of course it is possible to switch the auto-creation of jobdir off and just compose the file in memory if you do not want IO to slow you down.)
The wole lambda function is as follows:
p -> {
try (com.lowagie.text.Document doc = new com.lowagie.text.Document()) {
java.io.File jobdir = (java.io.File)p.get("jobdir");
String name = (String)p.get("first-name");
clojure.lang.PersistentVector transactions = (clojure.lang.PersistentVector)p.get("transactions");
java.io.File outputFile = new java.io.File(jobdir, "statement.pdf");
com.lowagie.text.pdf.PdfWriter instance = com.lowagie.text.pdf.PdfWriter.getInstance(doc,
new java.io.FileOutputStream(outputFile));
doc.open();
doc.add(new com.lowagie.text.Paragraph("Dear " + name + ","));
doc.add(new com.lowagie.text.Paragraph("Your statement is ready: "));
com.lowagie.text.Table table = new com.lowagie.text.Table(5);
table.setWidth(100);
table.setPadding(3);
table.setBorderWidth(2);
table.setHorizontalAlignment(com.lowagie.text.alignment.HorizontalAlignment.CENTER);
table.addCell("Date");
table.addCell("Description");
table.addCell("Debit");
table.addCell("Credit");
table.addCell("Balance");
table.endHeaders();
java.util.Iterator itr = transactions.iterator();
while(itr.hasNext())
table.addCell(itr.next().toString());
doc.add(table);
java.util.Map m = new java.util.HashMap();
m.put(clojure.lang.Keyword.intern ("file-path"), outputFile.getCanonicalPath());
return m;
} catch (com.lowagie.text.DocumentException | java.io.IOException de) {
java.util.Map m = new java.util.HashMap();
m.put("code", "ERROR");
m.put("status-message", de.toString());
return m;
}
}
If you now still want to test in REPL you can do so, just make sure you add a jobdir property and point it to your custom test folder – and also make sure you remove before further running the workflow.

Note: As I said, properties do not have to be only literals. They do not also have to be just data structures (maps or arrays) - here you can see we have a property that returns a java.io.File.
To switch from a literal to clojure expression in GUI, just click into the text box in then click the lambda icon on the right hand side to switch into the (clojure) expression mode. Here I am using clojure java interoperability to instantiate new File object: (java.io.File. "/path/to/folder")
Testing the workflow
Now we can run the workflow from GUI and see if the file gets generated. Click the run button and in the modal window select the :core system and tweak the properties if you wish. Then click start:

In the Jobs tab you can now see that the job got processed successfully:

Adding S3 and Email Delivery
Since we have already done a fair share of coding and made the point, we can take it easy and just use already predefined steps for S3 and SMTP from titanoboa's tasklet repository.
Maven dependencies for S3 and Email
We will follow instractions from that repository - first of all you will again have to add necessary Maven dependencies coordinates: [io.titanoboa.tasklet/aws-s3 "0.1.0"] and [io.titanoboa.tasklet/smtp "0.1.0"].
The resulting dependiencies should look as follows:
{:coordinates [[com.github.librepdf/openpdf "1.3.11"]
[io.titanoboa.tasklet/aws-s3 "0.1.0"]
[io.titanoboa.tasklet/smtp "0.1.0"]]
:require [[io.titanoboa.tasklet.aws.s3]
[io.titanoboa.tasklet.smtp]]
:import nil
:repositories {"central" "https://repo1.maven.org/maven2/"
"clojars" "https://clojars.org/repo"}}
Add S3 workflow step
Click on the "Add" button and enter a name for the new job: e.g. "s3-delivery".
Then switch to the step connecting mode and connect the first step with the second:
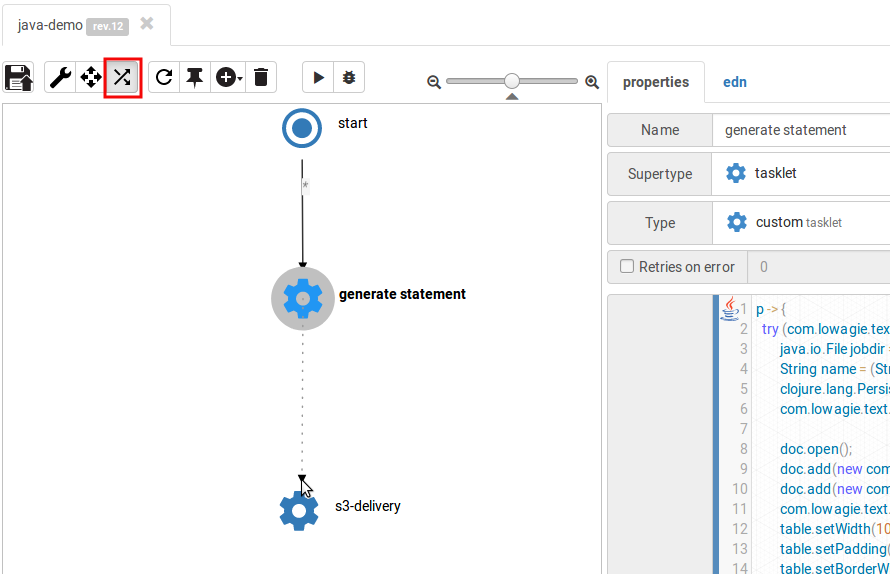
You can also see how the connecting works here.
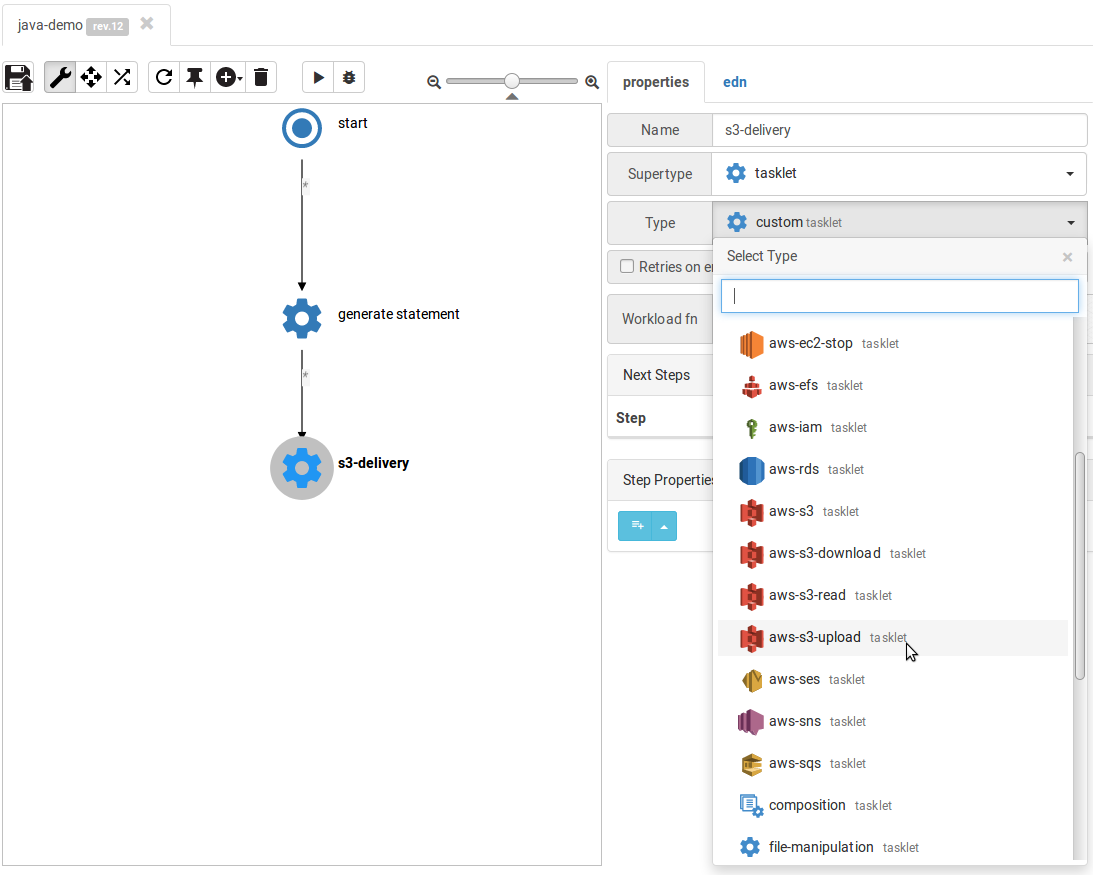
Switch back to properties editing mode and click on the new step, then change its type to "aws-s3-upload" and choose to merge everything pre-defined:
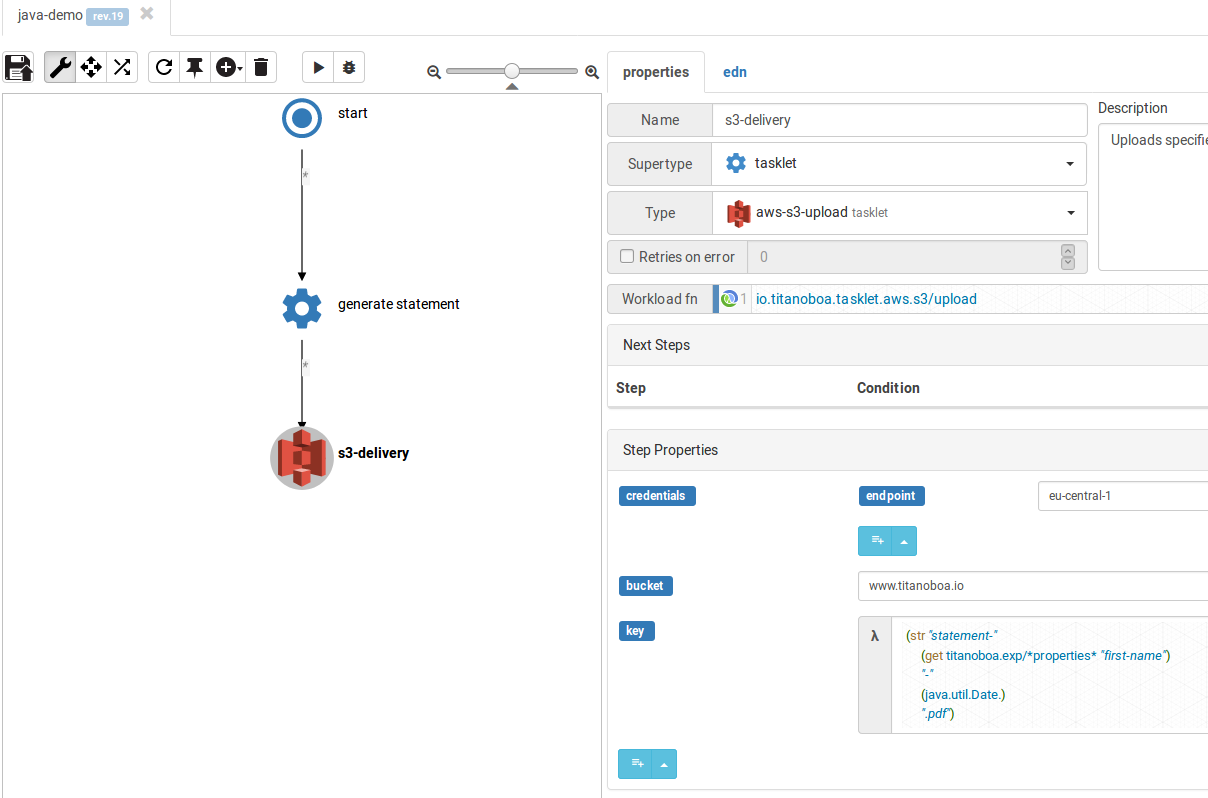
Update properties to match your S3 properties and credentials (I am not showing the credential here for obvious reasons). The file-path property can be removed as that one is already returned by the previous step.
Now you can run a new workflow job to see whether it works:
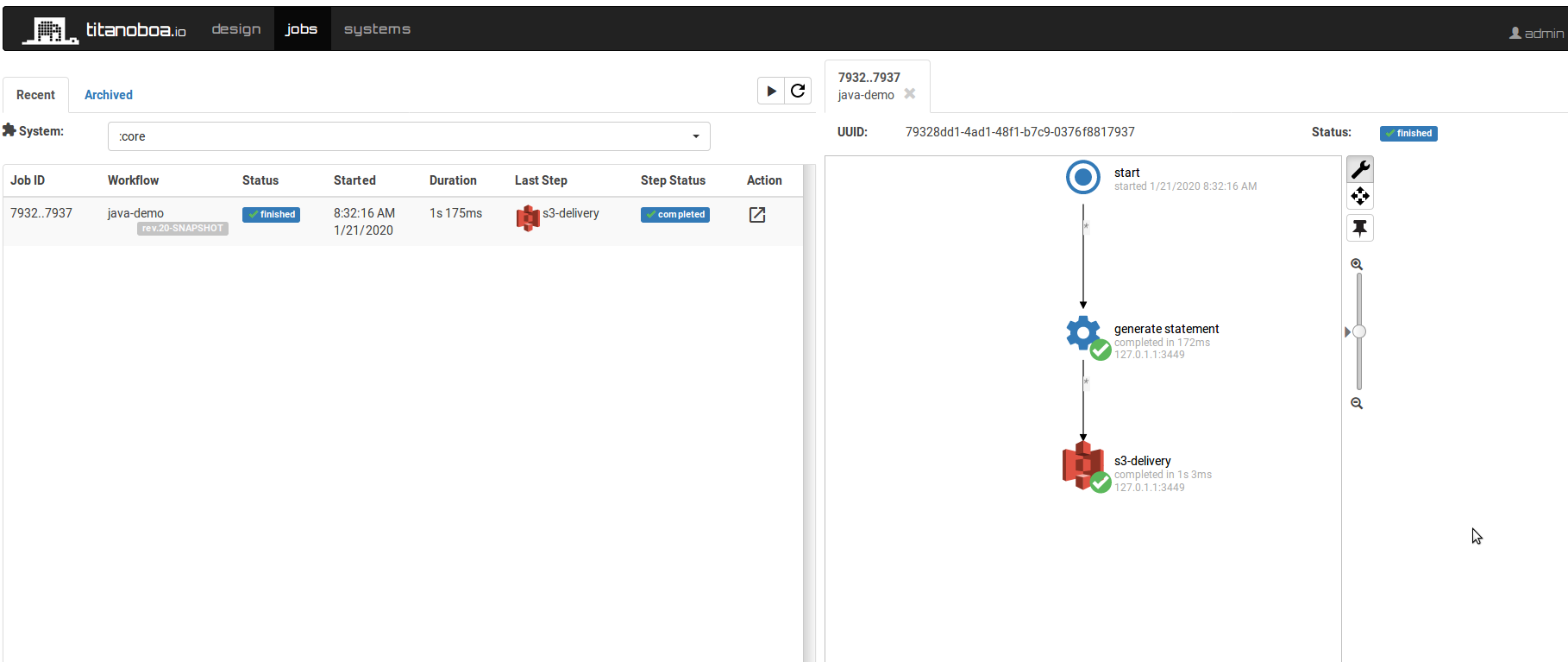
And it does! You should be able to see your statement in your S3 bucket. You should be also able to see resulting properties in the GUI:
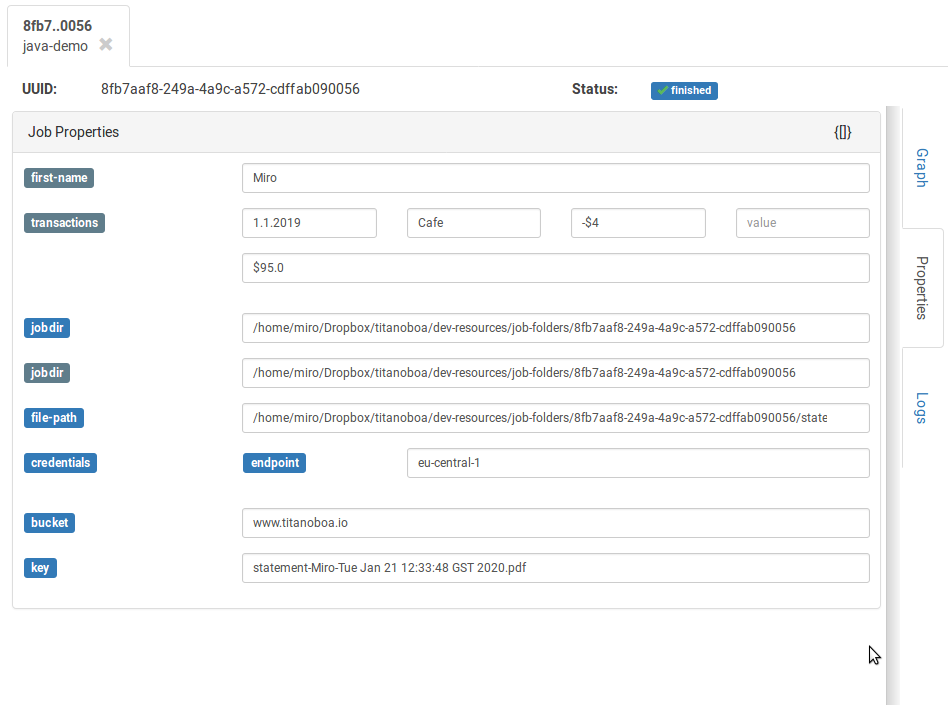
You can see that the file-path returned by the first step is actually there. And so are the other properties.
Note: Here you actually can observe that in GUI, the keyes in properties map can be of two different colours: blue denote instances of clojure.lang.Keyword which is a clojure literal - a keyword ,
the grey ones denote a simple java.lang.String. You can use both, java programers will understandably use String, while Clojure programmers might prefer keywords.
In same way as you added S3 step you can now add also an SMTP delivery.
Further notes on developing Java steps in titanoboa
For production purposes, java lambda inline code might not be the best approach. It is best for rapid prototyping, but you may want to also read about other options you have to code new workflow steps in java see section Developing custom workflow steps in Java in here.
Read more about titanoboa in our github wiki.