Will Embedded Clustering Kill Kubernetes?
TL;DR
- If you are building enterprise software, do not assume customers will use Kubernetes.
- You should not force your users/customers to use Kubernetes just to scale or make your application Highly Available.
- Instead, build your application platform-agnostic and embed some basic clustering capabilities in it.
- Provide clear guidelines how to scale and how to achieve high availability as well as how to use your product in virtualized environment and/or with containers / K8s.
In relationship with Kubernetes: It’s Complicated
Kubernetes (aka K8s) is by all means an incredible piece of software. But there is no denying that it is a complex piece of software - after all, the problems it is trying to solve are complex.
Premature Optimization
Some also say that in some cases its adoption might be just yet another attempt for a premature optimization: It might be great, but in case you are not the next Google or Netflix and you already have a working solution set up on couple of (or few tens of) VMs it might not be worth it: it would make some things easier on one hand while introducing another whole layer of complexity. Unless of course your primary goal is to build your team a better Resume.
Kubernetes is the New Application Server
Some of the ideas of Kubernetes are not new. Once upon a time dinosaurs called “Application Servers” (AS) were roaming the young planet Earth. They were the evolutions’ hope and had sentience on their road map just few release away. But somehow they got too vein, too bloated, too big and too complex and all it took for them to disappear forever was just one huge piece of a rock.
The idea behind Application Server was ingenious: just build your application, package in a zip file with some deployment descriptors and deploy it into AS – and that’s it! The rest will be magically handled by the AS: service discovery, horizontal scaling – clustering & high availability – as well as load balancing and security! This thing was there to change life of developers and make it just so so easy!
Sounds familiar?

The point that Kubernetes is the new AS has been made before.
Did Embedded Server Kill the Application Server?
One of the paradigm shifts that happened around the time when AS’ adoption dropped was heavier reliance on embedded Http servers and application containers. That is how for example Spring Boot was born: in the Java land, more and more people embedded a jetty server directly in their application because they realized that in 80% of use cases that is all that’s needed. And those 20% may have not been business critical enough to warrant the bloated complexity of Application Servers.
Can Embedded Clustering Kill Kubernetes?
Is Embedded Clustering even a thing? I just made up the term, but sure it is. It just means that some basic capabilities for clustering and high availability are embedded in you application. The extent depends on what your application is and who the users and use cases will be – so it might include some feature or it may not (e.g. service discovery and load balancing). In Java ecosystems it means that your Spring Boot application just uses JGroups or similar library to establish connections between cluster nodes, to perform load balancing and to handle potential failover. Or you may use Spring Cloud together with few libraries from Netflix OSS etc.
The bottom line is – if your application's production use may require Clustering and High Availability (and especially if you are a software vendor and/or you do not have full control over how will your application be used): Have basic clustering capabilities built into your application. Let users/customers have control over whether they will run it on bare metal, on VMs , or on K8s. Provide instructions and best practices for all the setups. But do not dictate to customers on what should be only an operations detail. For instance, if your “embedded” cluster relies on JGroups, it can quite easily integrate itself into Kubernetes.
Are we just re-inventing the wheel?
Ha! We've had this discussion already! Remember? Circa 2007:
Dev A: “We have this beautiful WebLogic farm here, see?”
Dev B: “Sorry, for this project I am going to go with an embedded Jetty.”
Dev A: “Are you insane?! WebLogic can already do all this plus much much more. Or maybe you like WebSphere more? You for sure just can’t be smarter than the whole industry!”
Dev B: “Sorry, I just think I do not need that much, for my use cases it seems sufficient and somehow I spend less time on embedded jetty than on all that XML configuration.” (that is how they called YAML back in the days).
Example: How Titanoboa’s "Embedded" Cluster Works
Just to give you an example of how I addressed clustering in one of my solutions - Titanoboa (my workflow platform for JVM): Instead of imposing some existing clustering solution onto the users (e.g. recommending K8s or anything similar), I decided to built some basic clustering and HA capabilities into it directly.
Titanoboa’s approach to clustering and (unlimited) scalability is dead simple: There is no master node. It just uses a message queue and all the nodes are broadcasting their status into that queue. You can add nodes during runtime as well as remove them. No configuration changes or “master node” restarts are needed. Any node can digest information from that broadcast (but only if it wishes to) and use it to provide you summary on cluster’s state or to distribute workload across the cluster.
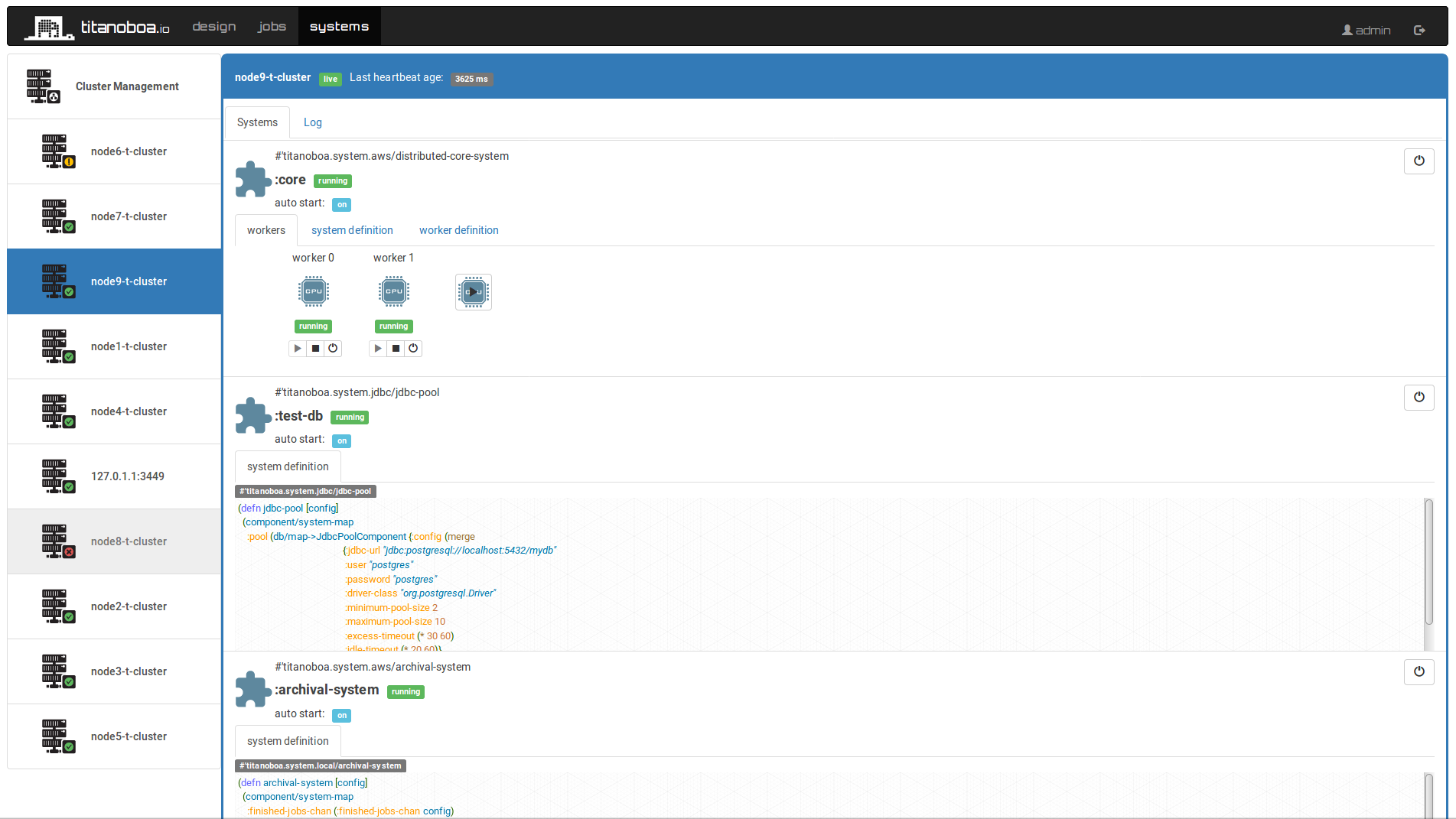
You can even have workflows run on Titanoboa that alter its own cluster – e.g. spin up 20 more nodes to help with a workflow processing etc.
E.g. a job to add another EC2 node into an AWS cluster may look as follows:
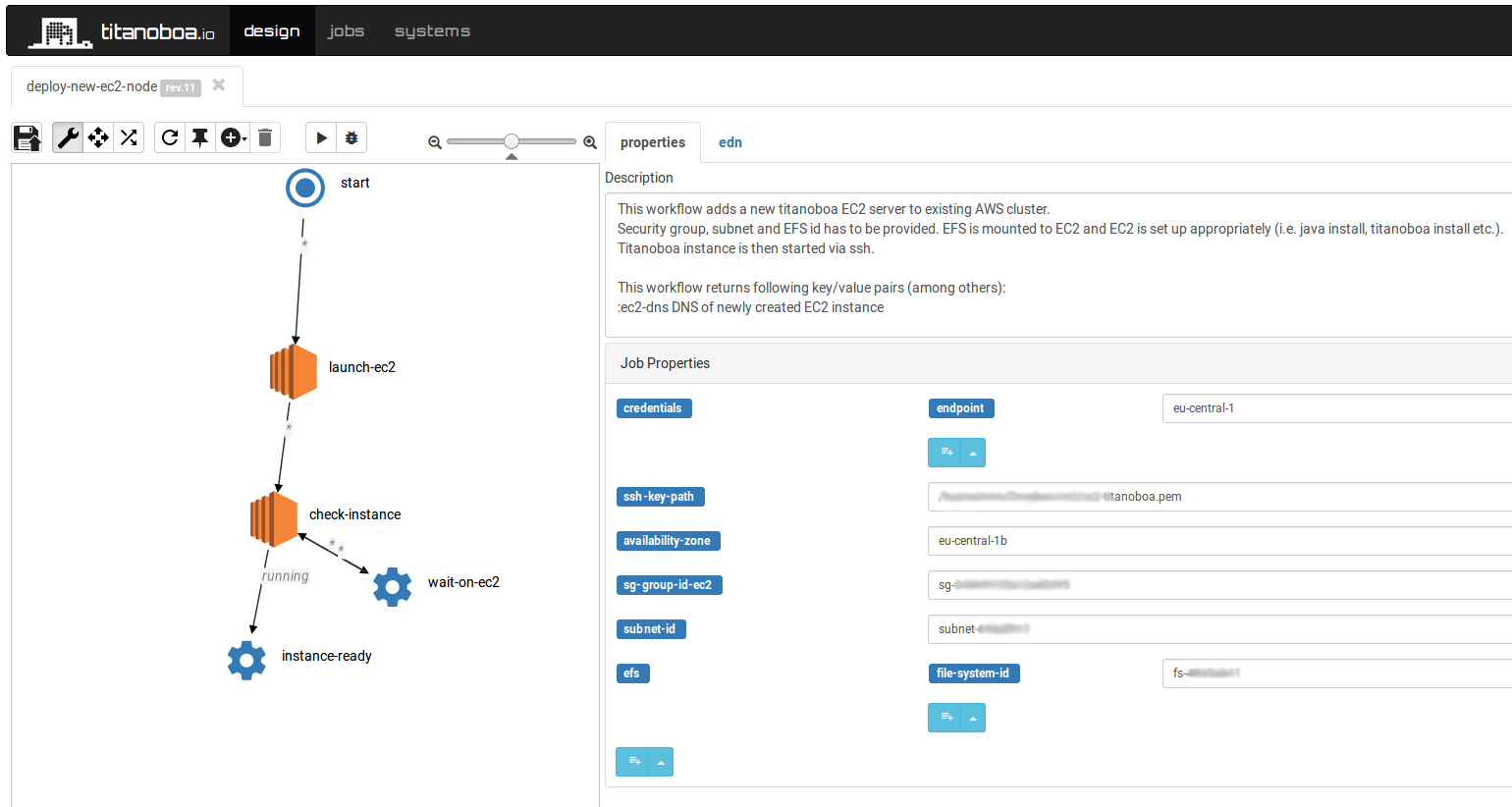
Since the setup is stateless by default it can work well in any type of setup – being it K8s or just running in a cloud on AMIs. But even without Kubernetess, you can see all cluster nodes in Titanoboa’s GUI, their state and you can use workflows to add more nodes or to bring some down etc.
Summary
If you are already an adopter of Kubernetes and especially if you are already using it across your entire enterprise then good on you, scale away.
If however you are considering using it for your next project or even imposing it as a dependency on your product as a vendor (!) - maybe take your time, explore whether you really need it first.
In microservices world, we had to learn the hard way that we still have to go Monolith First.
What I am simply proposing here is that in regards to scalability it might be also a good idea to go with a simple (embedded) clustering solution first.
Read more about titanoboa in our github wiki.